🦖 DINOv3: The Dinosaur That Ate All of Computer Vision
Time to say bye-bye to ResNet? 👋

Self-supervised learning (SSL) has long promised freedom from manual labels. Instead of begging humans to annotate cats and dogs, SSL teaches models to learn directly from raw pixels. DINOv3 is the latest big step in this journey and honestly, it's kind of a M O N S T E R (in a good way of course).
🤓 Why DINOv3 Matters
Unlike task-specific models, DINOv3 is built as a universal visual encoder. It learns rich global features (great for classification) and precise local features (essential for segmentation, depth, tracking). That's a rare combo, because previous models usually had to pick one side.

Typical task-specific model.
DINOv3 has a 7B PARAMETERS! And training such a vision model at the 7B parameter scale is not only about raw compute. It surfaces a number of stability and scalability problems that researchers had to carefully solve. Let's break down the key innovations that made DINOv3 possible.
🧲 Gram Anchoring: Saving Dense Features!
🚨 Problem: When training the huge 7B DINOv3 model for a long time, global metrics (like classification) keep improving as expected. But dense prediction tasks, like segmentation, start degrading after ~200k iterations. Why? 🤔 Patch-level features begin to “blur” - the model loses local detail, and similarity maps become noisy and less reliable.
✅ Solution: The idea is simple but clever: instead of forcing the patch features to stay in place directly, we preserve their relationships. We do this using the Gram matrix - a matrix of all pairwise dot products of patch features in an image.
We take a Gram teacher - an early snapshot of the model with high-quality dense features - and pushes the student model to match its Gram matrix:
- XS — L2-normalized patch features of the student
- XG — L2-normalized patch features of the Gram teacher
This way, the features themselves are free to move, but the structure of patch similarities remains intact.
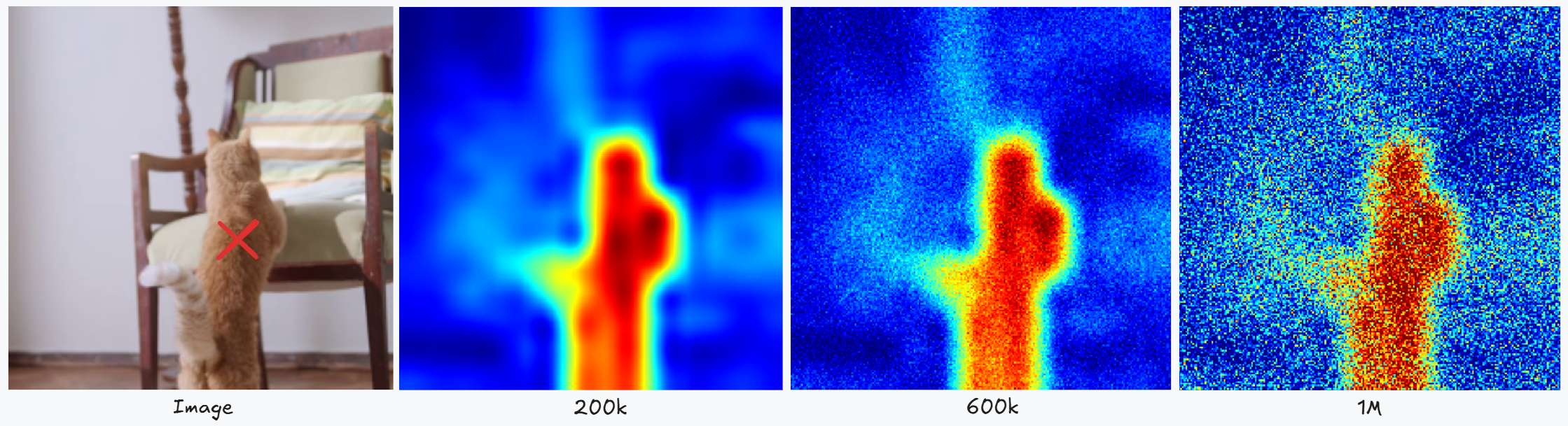
Change in cosine similarity between the red-marked patch and all other patches over training. As training continues, the model's features lose spatial localization, causing the similarity maps to become increasingly noisy.
🌍 Massive Data Curation
🚨 Problem: Scaling models blindly on raw web data can lead to noisy, unbalanced
datasets that harm
generalization. A model of this size needs diverse but clean input to avoid
memorization
and overfitting.
✅ Solution: The DINOv3 team curated a dataset of 1.6 billion+
images, carefully
filtered to remove low-quality samples and ensure diversity. This massive yet controlled
dataset
provides the foundation for the model's broad generalization across domains and tasks.

📏 A Scalable Family of Models
🚨 Problem: While a 7B parameter model is great for research, it's impractical
for most real-world
deployments due to cost and latency.
✅ Solution: The team distilled the giant model into a whole family of
ViTs,
ranging from small (ViT-S, ~21M params) to large (ViT-H+, ~0.8B params). These distilled
versions
inherit most of the power of the 7B model but are efficient enough for everyday use
cases.
This makes DINOv3 both a research breakthrough and a practical tool.
🛠 Post-Training Tricks
🚨 Problem: Even after training, models may fail to adapt to higher resolutions,
lack zero-shot text
understanding, or be too rigid for transfer.
✅ Solution: DINOv3 employs several clever post-training
strategies:
- Resolution Scaling: adapts the model to work with high-res inputs (512px, 768px, and even 4K).
- Distillation: compresses knowledge from the huge teacher into smaller, faster students.
- Text Alignment: adds a contrastive training phase that links image features with captions, enabling zero-shot multimodal capabilities similar to CLIP but with stronger dense representations.
Together, these innovations solve the fundamental problems of instability, noisy data, impractical scale, and limited adaptability.
🏁The result: a vision foundation model that is not only state-of-the-art in research benchmarks but also practical and versatile for real-world computer vision applications.
📊 Benchmarks
The frozen 7B model already crushes benchmarks. Add tiny task-specific heads and suddenly you've got state-of-the-art object detection, segmentation, depth estimation, and even 3D view understanding. All from the same backbone.
🎥 The Fun Part: Object Tracking Demo
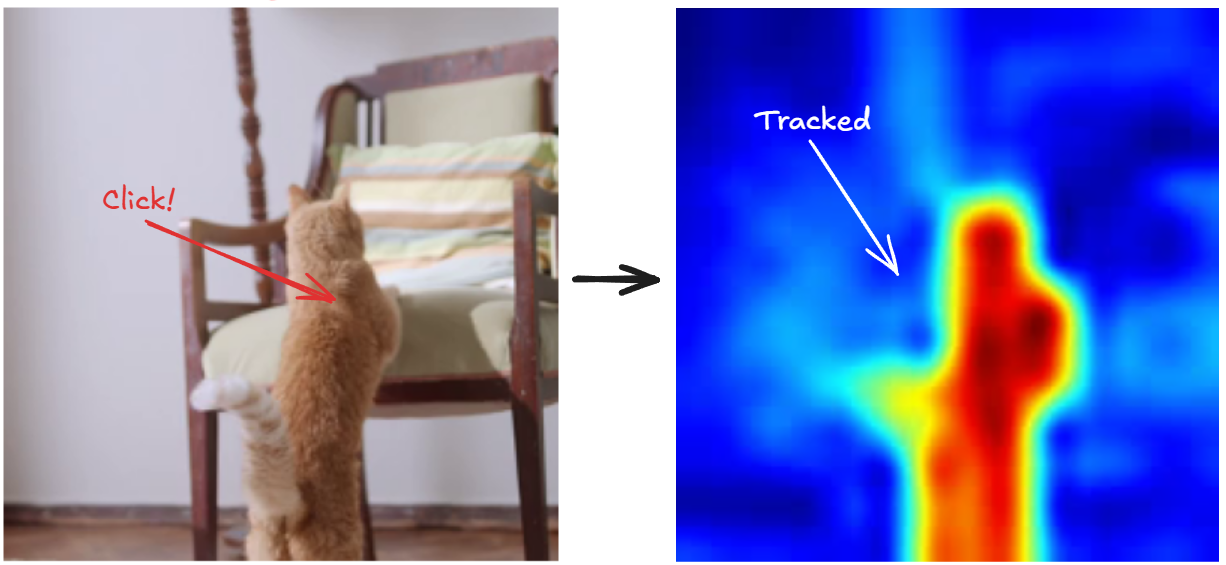
Alright, enough theory. Here's the cool part: I want to show you how to simply use DINOv3 for video object tracking with just a mouse click.
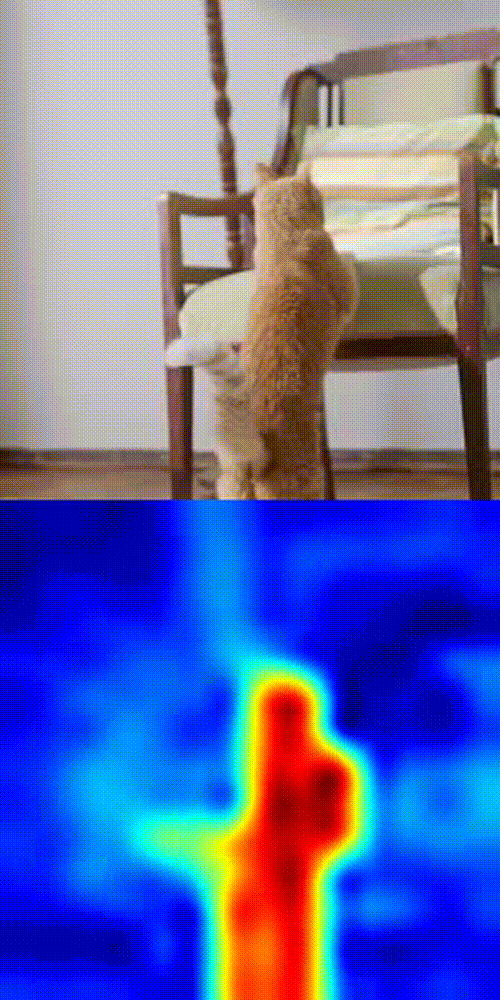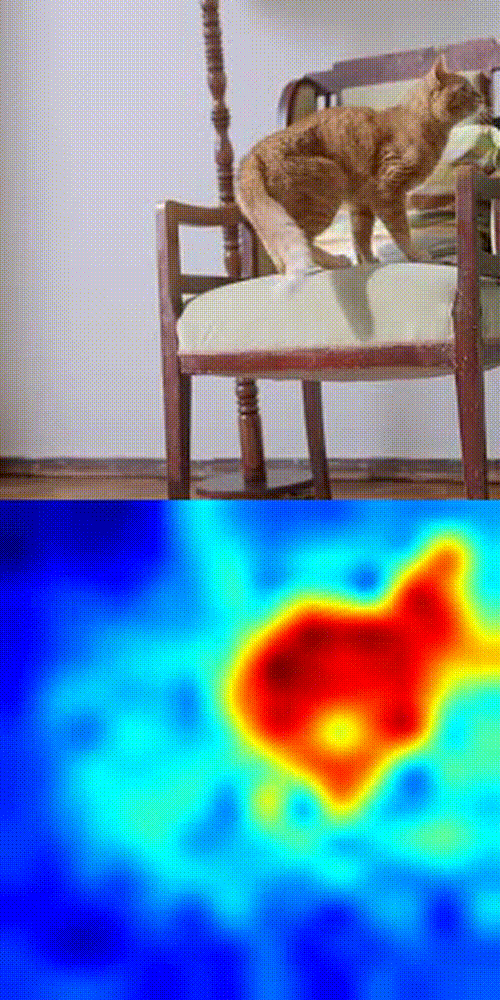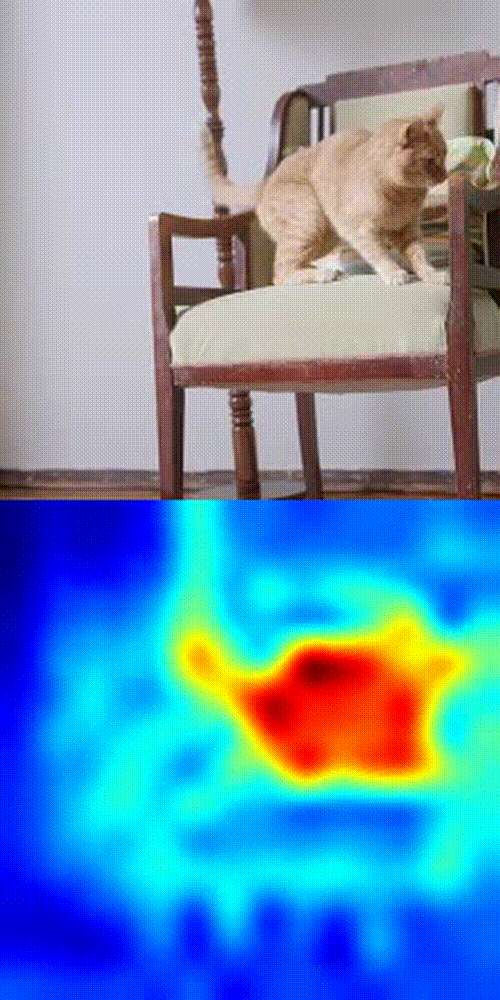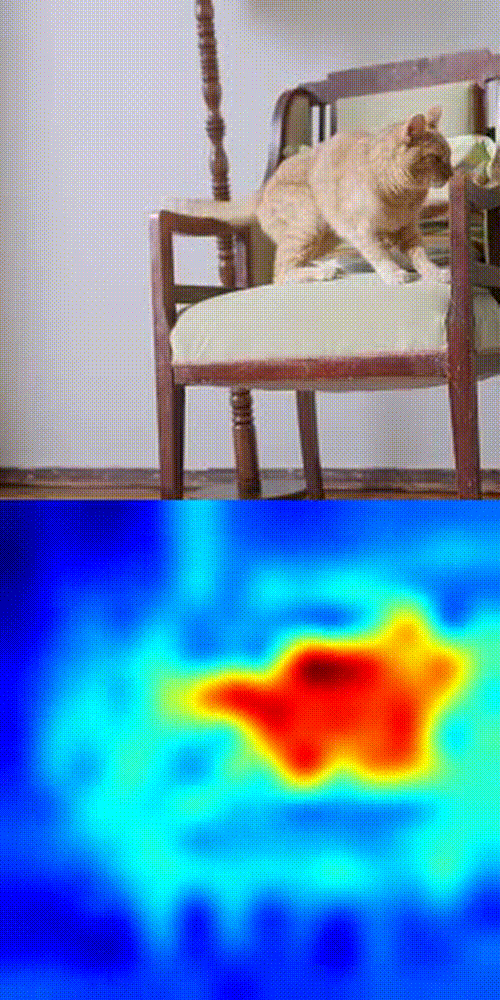
Cat tracking example
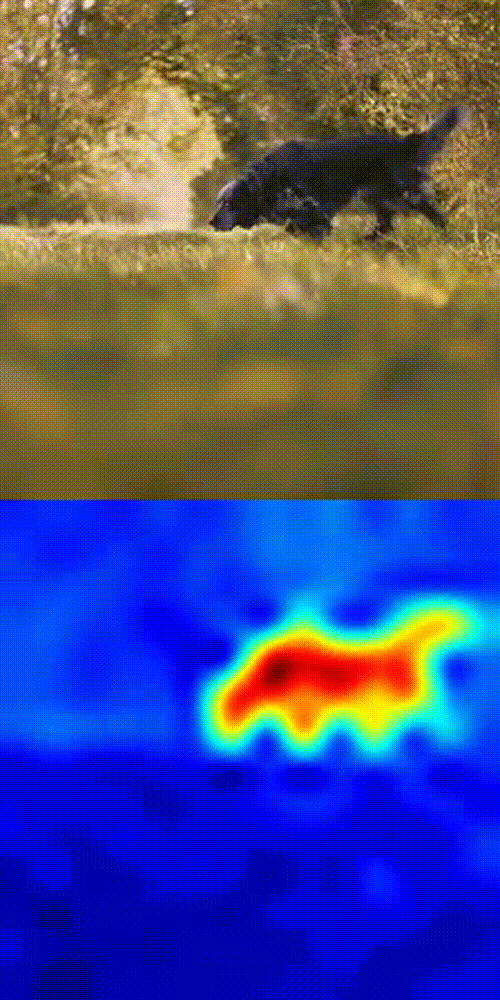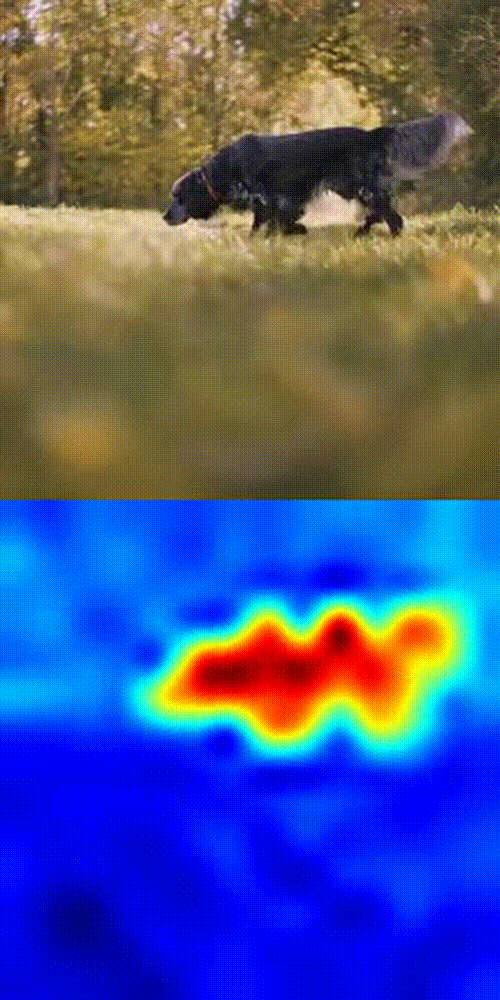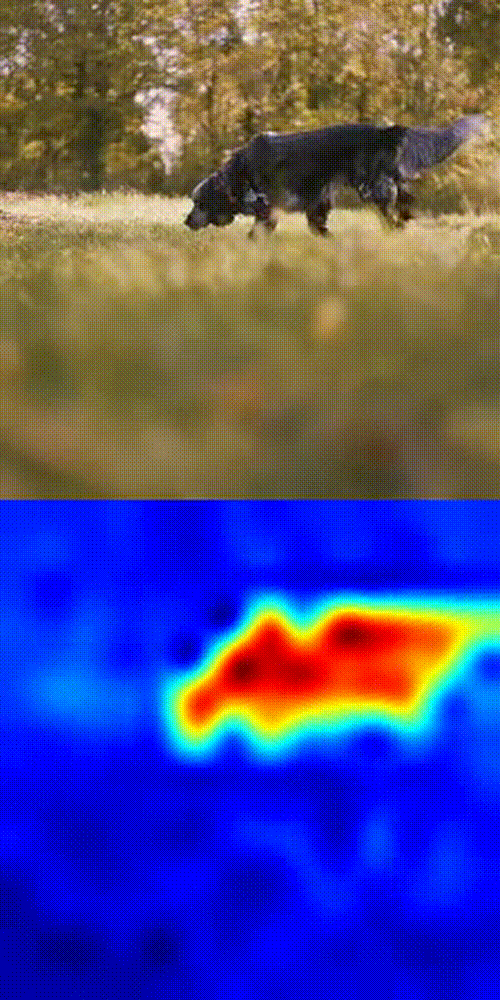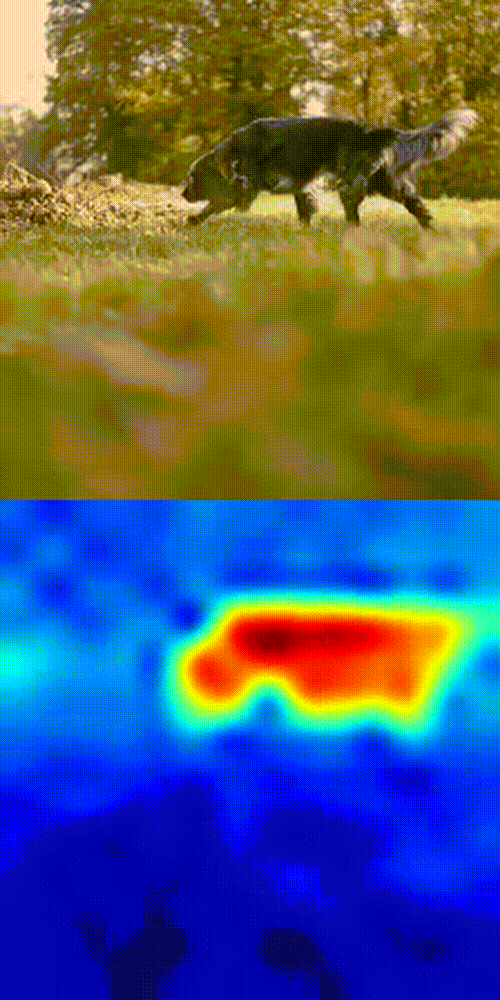
Dog tracking example
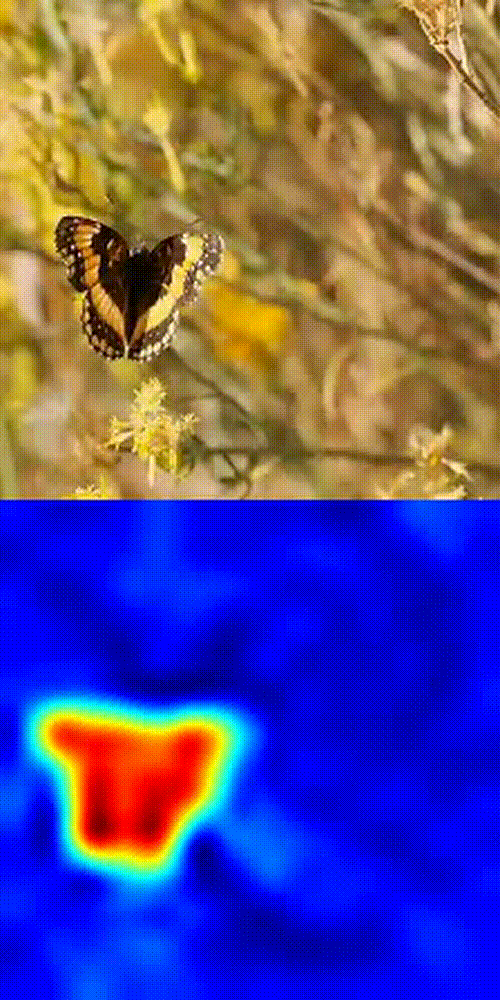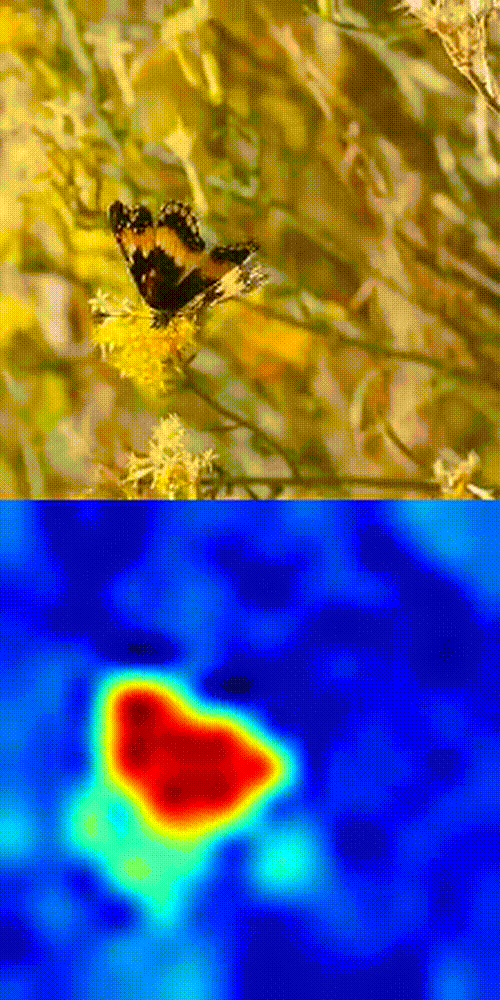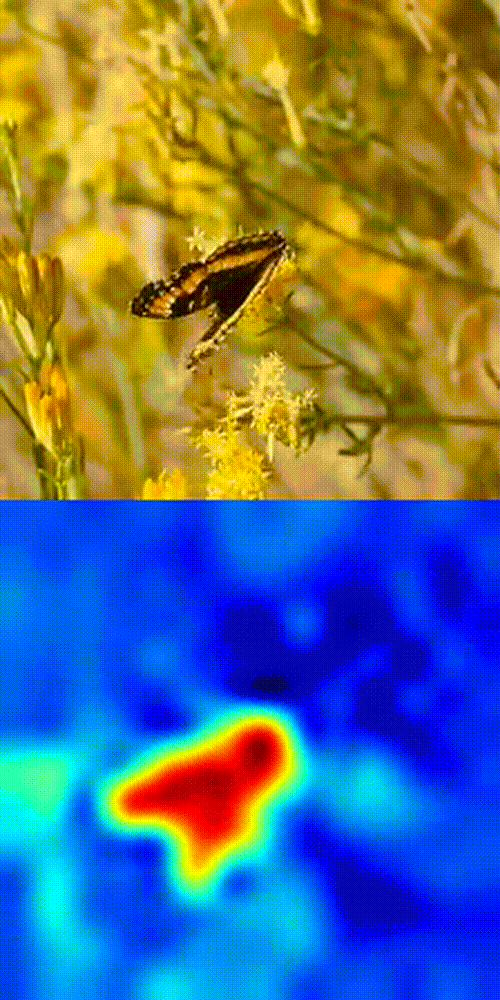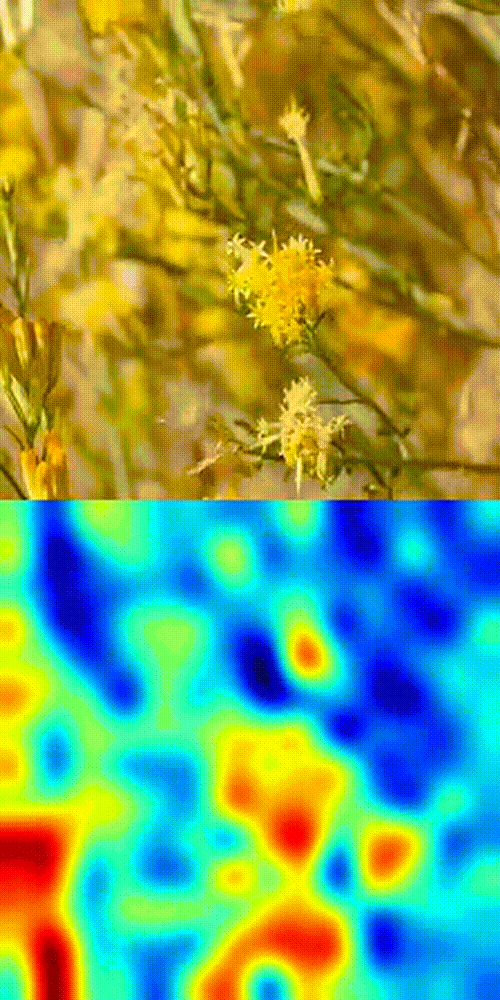
Butterfly tracking example
What is this thing is doing:
- Take the first frame of your video.
- Click the object you want to track.
- DINOv3 splits the frame into patches and encodes each into a feature vector.
- Compare the selected patch with patches in future frames using cosine similarity.
- Boom 💥- you get a similarity heatmap (more orange = more likely your object).
Basic demo example.
This works because DINOv3's patch-level features are dense, consistent, and spatially precise. No fine-tuning. No magic tricks. Just pure SSL power in action.
Era of ResNet is over, Press F 🫡
🔗 Here is the repo: Object Tracking GitHub
The Final Words
DINOv3 is more than just a research flex. It shows that with talent of researchers and involved scientists SSL can beat supervised methods while staying general-purpose. From dense tasks to global embeddings, from 7B giants to edge-friendly distilled models, it sets a new bar for foundation vision models.
👉 Big thanks to the authors of DINOv3 for this masterpiece! They proved that dinosaurs aren't extinct. They're running your vision models now. 🦖